
Introduction
Facial Landmarks Localization,也称为Face Alignment,是人脸一个非常热门的方向,它的作用就是准确定位人脸关键点。Pose Estimation近年来也得到了越来越多的关注,常常被用于动作分析、以及抖音尬舞机等场景。因Facial Landmarks Localization和Pose Estimation有着比较大的相似性,所以本文将两者放在一起介绍。
关于Pose Estimation,目前学术界开源的算法库有如下几种:
@LucasXU注:本文长期更新。
Stacked hourglass networks for human pose estimation
说到Pose Estimation,就不得不提Hourglass Network,Hourglass Network是Pose和Face Alignment方向一个非常经典的工作,而且结构上也非常简洁,和常规的网络设计idea类似,依然是basic Hourglass module的重复叠加。
通过repeated pooling and upsampling,以及intermediate loss supervision,特征在不同scale得到了联合,从而可以最好地capture到身体不同部位的spatial relationship,Hourglass Network在相关benchmark上均取得了非常好的性能。
Stacked Hourglass Network的网络结构图如下: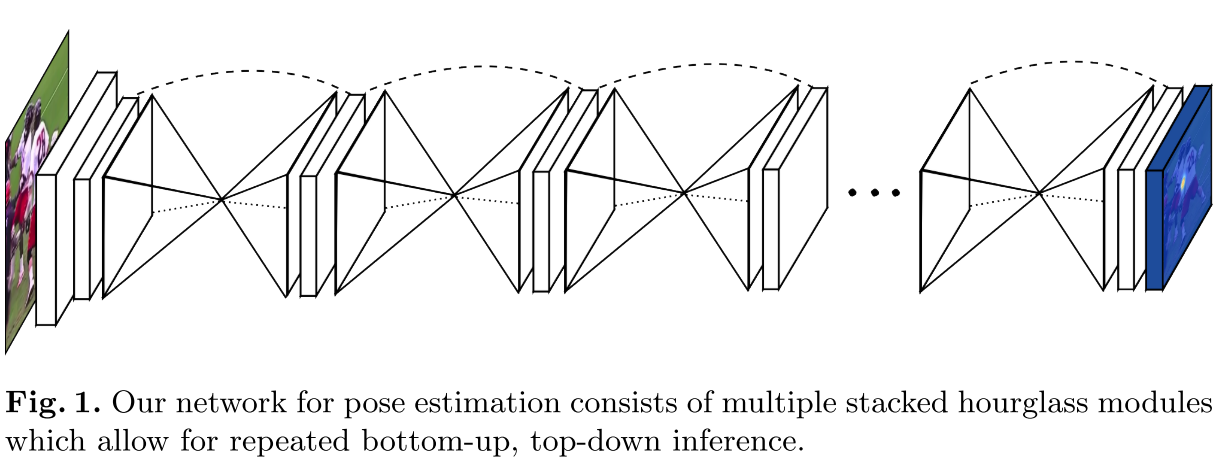
Hourglass module的设计,和图像分割/Encode-Decoder结构中的上采样有点类似,但是这些结构通常encoder的结构比decoder的结构更加heavy,而Hourglass module中donwn-sampling structure和up-sampling structure是完全对称的。
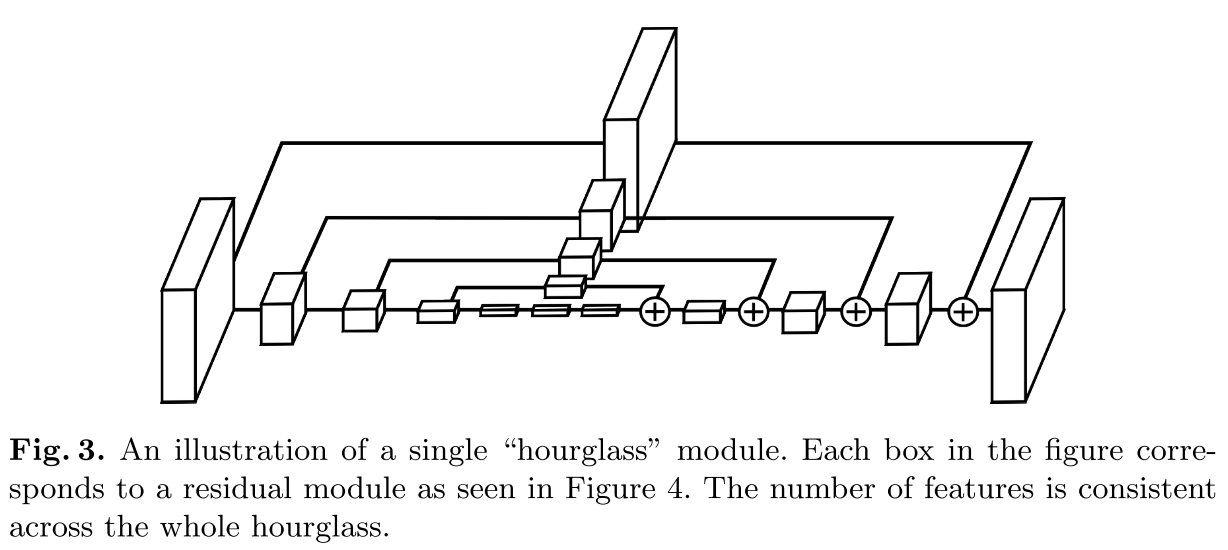
Network Architecture
Hourglass Design
Hourglass module的设计思想就是capture information at every scale的需求,local evidence对识别face/hand的feature很有用,而final pose estimation则需要full body understanding。Conv/Max-Pooling layers用于将feature下采样到low resolution,在每个Max-Pooling layer,网络开辟新的branch并应用更多的Conv于pre-pooled resolution。在获得最低resolution的feature后,网络开始up-sampling操作,并将across scale的feature进行组合。为了将across two adjacent resolution的信息进行整合,作者采用了nearest neighbor upsampling + Element-wise addition操作。在抵达网络output resolution时,应用两个consecutive rounds of $1\times 1$ Conv来产生最终的预测结果。网络的输出是一系列heatmap,每一个heatmap预测一个关节的presence at each and every pixel的概率。
Stacked Hourglass with Intermediate Supervision
因本身堆叠的重复结构,所以也可在中间层添加intermediate supervision,并且作者通过实验证明了,添加intermediate supervision能带来更好的效果提升。
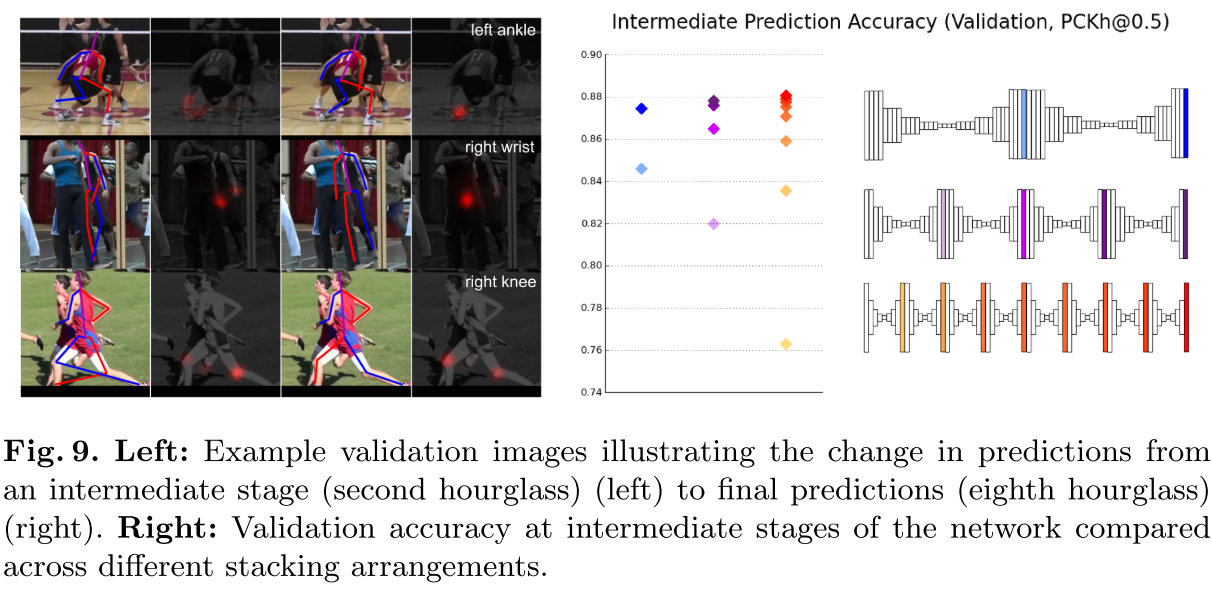
Local and global cues are integrated within each hourglass mod- ule, and asking the network to produce early predictions requires it to have a high-level understanding of the image while only partway through the full net- work. Subsequent stages of bottom-up, top-down processing allow for a deeper reconsideration of these features.
在训练阶段,MSE Loss应用于predicted heatmap和groundtruth heatmap (consisting of 2D gaussian centered on joint location)。
A Mean Squared Error (MSE) loss is applied comparing the predicted heatmap to a ground-truth heatmap consisting of a 2D gaussian (with standard deviation of 1 px) centered on the joint location. To improve performance at high precision thresholds the prediction is offset by a quarter of a pixel in the direction of its next highest neighbor before transforming back to the original coordinate space of the image.
Reference
- Newell, Alejandro, Kaiyu Yang, and Jia Deng. “Stacked hourglass networks for human pose estimation.” European conference on computer vision. Springer, Cham, 2016.
- Sun, Ke, et al. “Deep High-Resolution Representation Learning for Human Pose Estimation.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019.
- Tompson, Jonathan J., et al. “Joint training of a convolutional network and a graphical model for human pose estimation.” Advances in neural information processing systems. 2014.