
AI in Production
从AlexNet让深度神经网络重回视野,到AlphaGo被广为人知,AI得到了越来越多的关注。时间到了2020年,与前些年不少公司热衷于发paper、打比赛做PR不同,现在越来越看重AI落地。基于此背景,本文旨在记录AI在各行各业落地的一些行业解决方案、insightful Paper、以及笔者本人的一些思考,希望能给大家一些启发。
Geometry Supervised Pose Network for Accurate Retail Shelf Pose Estimation
Keywords: AI,CV,新零售,货架姿态估计
Paper: Geometry Supervised Pose Network for Accurate Retail Shelf Pose Estimation
Code: RSPD
AI赋能零售行业,最常见的落地场景有以下几种:
- 刷脸结算:能提高结算效率、方便零售商做VIP客源管理,熟客管理,以及提高趣味性、增强与用户之间的互动,且刷脸的屏幕也是很好的广告投放地点;涉及的主要技术点是人脸识别。
- 商品识别:用于货架排面分析,竞品分析,主要motivation是这样的:所有生意都是基于流量的生意,对于电商这种线上流量,用户的每一次搜索,平台如何对商品进行排序,则会直接影响商家的转化率,而在线下呢,用户进店,商品如何摆放、摆在什么位置能促使顾客下单,是一个非常值得斟酌的点;涉及的主要技术是目标检测、货架姿态估计、分类、ReID等等。
- 客流分析:主要还是转化率的问题,如果大家知道漏斗模型,就不难理解了。假设你开了一家便利店,开在某街道,这个地方每天的人流量是2W,到最终下单成交可能只有5%。那么扩大基数,也是保证交易额增加的要点!通俗点说,把门店开在热门地区,是大家的共识。当然,现在也有一些新零售公司,开店并没有选在热门地段(毕竟房租贵),而是选在稍微偏远的地段,然后通过打造品牌效应及外卖模式,也是可行的,这里涉及到商业模式的问题,不是本文讨论的重心;涉及的主要技术是Counting。
- 动线:主要是对店内人群活动轨迹进行跟踪,生成热力图与活动轨迹,来辅助商家进行决策;涉及的主要技术是Visual Tracking和ReID。
- 图搜:即以图搜图,线下逛商场看上了某裙子,掏出手机拍张照,搜同款,找到更便宜的再下单。涉及的主要技术是Image Retrieval和Metric Learning。
回归主题吧,这篇paper主要介绍了一种单目3D货架姿态估计方法,network architecture和idea也非常简单,属于非常实用的类型,且作者也公开了code和dataset (目前只有GitHub地址)。
货架姿态估计,与学术界常见的Head Pose Estimation,其实并没有本质区别,主要难点还是在于货架姿态的数据集和annotation相比于人体头部更难采集。算法层面,主流的方案还是基于DL regression的方法,即一个backbone (如ResNet/DenseNet/SENet等) 提取特征,然后输出3个branch,采用某种regression loss (例如MSE/L1/Smooth L1) 等去回归 yaw/roll/pitch angle。这里一个比较有代表性的工作是HopeNet。货架姿态估计在整个商品识别流程里主要起到reject low-quality images的作用,因为拍摄过于倾斜的货架会严重影响后续的排面分析准确性。
@LucasXU注:工业界通常不会采用太复杂的模型,一是可解释性极差;二是复杂度极高,莫说跑在edge device了,就是跑在GPU server也扛不住。到最后一看,一顿操作猛如虎,上你算法带来的收益还抵不上维护V100机器的开支,那就尴尬了。所以我觉得很多顶会Workshop的paper还是非常有价值的,这些paper往往是又简单又work。
Network Architecture
先看看网络结构: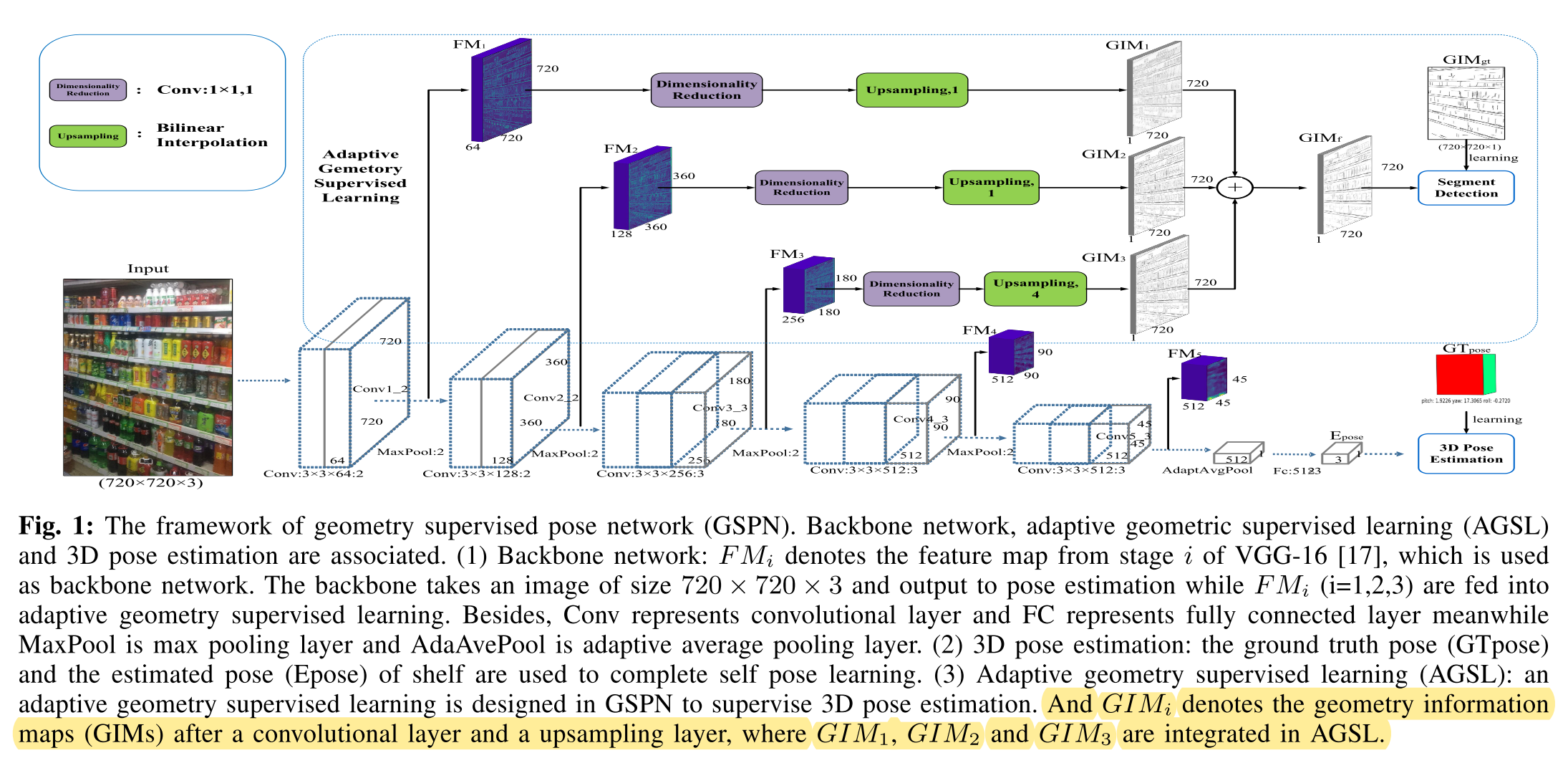
一张平平无奇的RGB image作为输入,VGG16作为backbone提取特征,并且将不同Conv layer的feature map进行降维、上采样(bilinear interpolation)、融合来获取multi-level & multi-scale 信息。因高层的$FM_4$和$FM_5$包含了丰富的semantic meaning,因此用来做Pose Estimation。然而,包含太丰富的semantic information会增加redundant noise,基于此,作者设计了 adaptive geometric supervised learning (AGSL) 模块来辅助GSPN学习,其中,$GIM_{gt}$通过LSD算法生成,通过BCE Loss来从低层feature $FM_1$, $FM_2$, $FM_3$中学习geometric properties。
Loss Function
GSPN模型的loss如下如所示,也是常见的joint loss结构:
令$l_{side1}$, $l_{side2}$, $l_{side3}$分别为upsampling layers 1,2,3的loss,$\hat{Y}_{side}$是每个side的输出,$Y$是ground truth geometry information map $GIM_{gt}$,则有:
$$
\hat{Y}_{side}^{(i)}=\sigma (\hat{A}_{side}^{(i)})
$$
$$
l_{sidei} = α_i L_{BCE}(Y, \hat{Y}_{side}^{(i)})
$$
$$
L_{BCE} = -\frac{1}{n}\sum_{j=1}^n (y_j log\hat{y}_j + (1-y_j)log(1-\hat{y}_j))
$$
Fuse loss定义为:
$$
l_{fuse}=L_{BCE}(Y, \hat{Y}_{fuse})
$$
其中
$$
\hat{Y}_{fuse}=\sigma (\sum_{i=1}^3h_i \hat{A}_{side}^{(i)})
$$
此外,yaw/pitch/raw 3个角度的loss为L1 loss。
最终的loss为:
$$
L_{RES}=\beta l_{LINEAR} + (1-\beta)l_{3D-POSE}
$$
其中:
$$
l_{LINEAR}=l_{fuse} + l_{side1} + l_{side2} + l_{side3}
$$
$$
l_{3D-POSE}=l_{yaw} + l_{roll} + l_{pitch}
$$
下图是3D shelf pose sample:
这篇paper idea比较简单,但是却非常实用;算法方面主要创新点在于设计了AGSL模块,用$GIM_{gt}$作为supervision来更好的学习geometric信息,来提升shelf pose estimation的精度。Ablation study请阅读原文,另外就是作者构建shelf pose数据集——RSPD的做法很值得参考,详情可阅读原文,此处不赘述了。
References
- Mou Y, Huang Z, Lin L, et al. Geometry Supervised Pose Network for Accurate Retail Shelf Pose Estimation[J]. IEEE Transactions on Industrial Informatics, 2020.
- Ruiz N, Chong E, Rehg J M. Fine-grained head pose estimation without keypoints[C]//Proceedings of the IEEE conference on computer vision and pattern recognition workshops. 2018: 2074-2083.