
Introduction
AIGC 在各行业得到了广泛的应用,相应的算法改进也层出不穷。本文重点不在于梳理具体的生成式模型,而在于如何对 AIGC 模型效果进行合理、科学的评价。
Methods
Inception Score
Paper: A note on the inception score
This metric is motivated by demonstrating that it prefers models that generate realistic and varied images and is correlated with visual quality. TheInception Scoreis a metric for automatically evaluating the quality of image generative models. This metric was shown to correlate well with human scoring of the realism of generated images from the CIFAR-10 dataset. TheISuses an Inception v3 Network pre-trained on ImageNet and calculates a statistic of the network’s outputs when applied to generated images.
$$
IS(G)=exp(\mathbb{E}_{x\sim p_g}D_{KL}(p(y|x)||p(y)))
$$
where $x\sim p_g$ indicates that x is an image sampled from $p_g$, $D_{KL}(p||q)$ is the KL-divergence between the distributions $p$ and $q$, $p(y|x)$ is the conditional class distribution, and $p(y) = \int_x p(y|x)p_g(x)$ is the marginal class distribution. The exp in the expression is there to make the values easier to compare, so it will be ignored and we will use $ln(IS(G))$ without loss of generality.
In the general setting, the problems with the Inception Score fall into two categories:
- Suboptimalities of the Inception Score itself
- Inception Score is sensitive to small changes in network weights that do not affect the final classification accuracy of the network
- score calculation and exponentiation
- Problems with the popular usage of the Inception Score
Fréchet Inception Distance
Paper: Gans trained by a two time-scale update rule converge to a local nash equilibrium
FIDmeasures the average distance between generated images and reference real images, and thus fails to encompass human preference that is crucial to text-to-image synthesis in evaluation. The author claims thatFIDcaptures the similarity of generated images to real ones better than theInception Score.
CLIPScore
Clipscore: A reference-free evaluation metric for image captioning
We hypothesize that the relationships learned by pretrained vision+language models (e.g., ALIGN (Jia et al., 2021) and CLIP (Radford et al., 2021)) could similarly support reference-free evaluation in the image captioning case. Indeed, they can: we show that a relatively direct application of CLIP to (image, generated caption) pairs results in surprisingly high correlation with human judgments on a suite of standard image description benchmarks (e.g., MSCOCO (Lin et al., 2014)). We call this process CLIPScore (abbreviated to CLIP-S). Beyond direct correlation with human judgments, an information gain analysis reveals that CLIP-S is complementary both to commonly reported metrics (like BLEU-4, SPICE, and CIDEr) and to newly proposed reference-based metrics (e.g., ViLBERTScore-F(Lee et al., 2020)).
To assess the quality of a candidate generation, we pass both the image and the candidate caption through their respective feature extractors. Then, we compute the cosine similarity of the resultant embeddings. For an image with visual CLIP embedding $v$ and a candidate caption with textual CLIP embedding $c$, we set $w=2.5$ and compute CLIP-S as:
$$
CLIP-S(c, v)=w\times max(cosine(c, v), 0)
$$
CLIP-S can additionally be extended to incorporate references, if they are available. We extract vector representations of each available reference by passing them through CLIP‘s text transformer; the result is the set of vector representation of all references, $R$. Then, RefCLIPScore is computed as a harmonic mean of CLIP-S, and the maximal reference cosine similarity, i.e.,
$$
RefCLIP-S(c, R, v)=H-Mean(CLIP-S(c, v), max(max_{r\in R} cos(c, r), 0))
$$
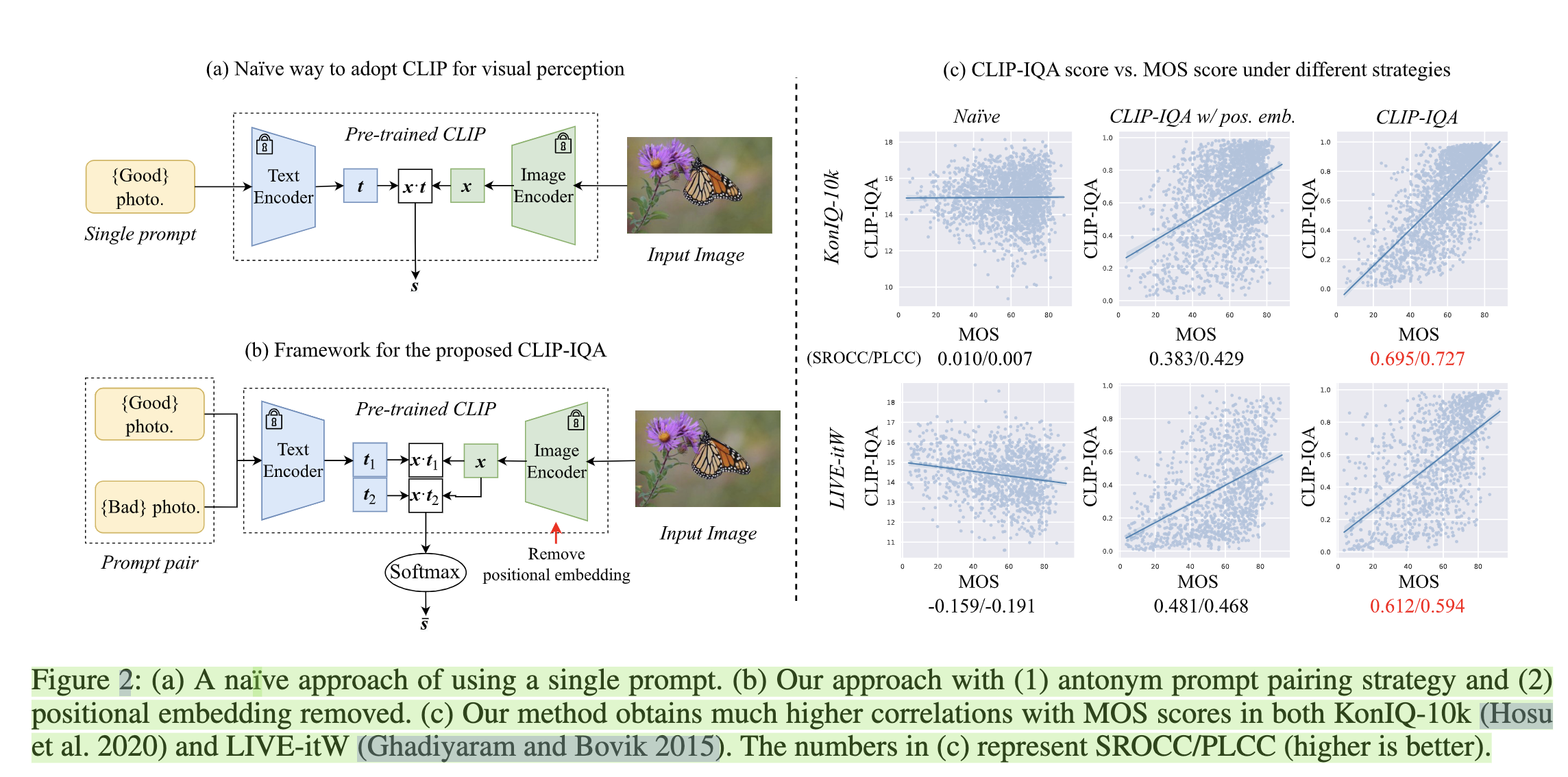
Exploring clip for assessing the look and feel of images
The term look represents image quality, feel stands for image aesthetic.
作者提出了一种直接利用 CLIP 模型来表达 image aesthetic & image quality 的方法:直接用 good photo 和 bad photo 作为 prompt,得到 prompt text embedding $t_i$,再计算其与 image embedding $x$ 的 cosine similarity $s_i, i\in \{0, 1\}$,再计算 $s_i$ 的 softmax probability 即可得到最终结果。
Reference
- Barratt, Shane, and Rishi Sharma. “A note on the inception score.” arXiv preprint arXiv:1801.01973 (2018).
- Heusel, Martin, et al. “Gans trained by a two time-scale update rule converge to a local nash equilibrium.” Advances in neural information processing systems 30 (2017).
- Wang, Jianyi, Kelvin CK Chan, and Chen Change Loy. “Exploring clip for assessing the look and feel of images.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 2. 2023.
- Hessel, Jack, et al. “Clipscore: A reference-free evaluation metric for image captioning.” arXiv preprint arXiv:2104.08718 (2021).
- Wang, Jianyi, Kelvin CK Chan, and Chen Change Loy. “Exploring clip for assessing the look and feel of images.” Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 37. No. 2. 2023.