
Introduction
大模型的训练通常包含两个阶段:self-supervised pre-training 来学习 general representation(近些年的趋势是堆大模型 + 自监督学习作为 Foundation Model),典型的代表性算法有 BERT、MAE、MoCo 系列以及 CLIP 为代表的多模态预训练大模型等supervised fine-tuning 在下游任务上进行适配SFT (Supervised Fine-tuning) 主要指的是第二部分,在模型参数量/数据量越来越大的背景下,full fine-tuning 成本太高,因此学术界&工业界开始探索 PEFT (Parameter Efficient Fine-tuning)。PEFT 不仅能极大地提升 fine-tuning 效率,也能够很好地处理 catastrophic forgetting 以及 OOD (Out of Distribution) 问题。
FT 方式
DMT
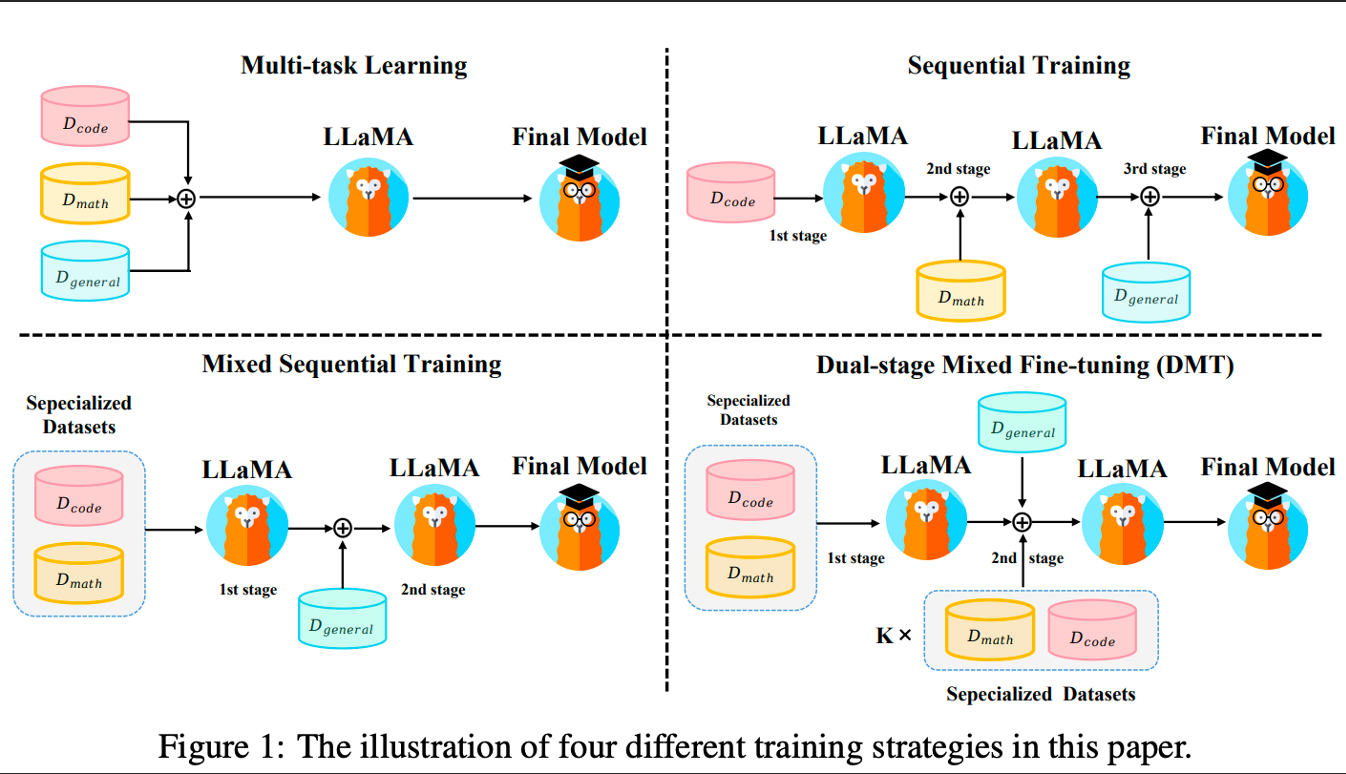
大模型混合多种能力项数据进行微调时,会呈现高资源冲突,低资源增益的现象。《HOW ABILITIES IN LARGE LANGUAGE MODELS ARE AFFECTED BY SUPERVISED FINE-TUNING DATA COMPOSITION》提出的 DMT(Dual-stage Mixed Fine-tuning) 策略通过在第一阶段微调特定能力数据,在第二阶段微调通用数据+少量的特定能力数据,可以在保留通用能力的同时,极大程度地挽救大模型对特定能力的灾难性遗忘,这为 SFT 的数据组成问题提供了一个简单易行的训练策略。值得注意的是,第二阶段微调时混合的特定能力数据量需要根据需求而定。
Deep Incubation
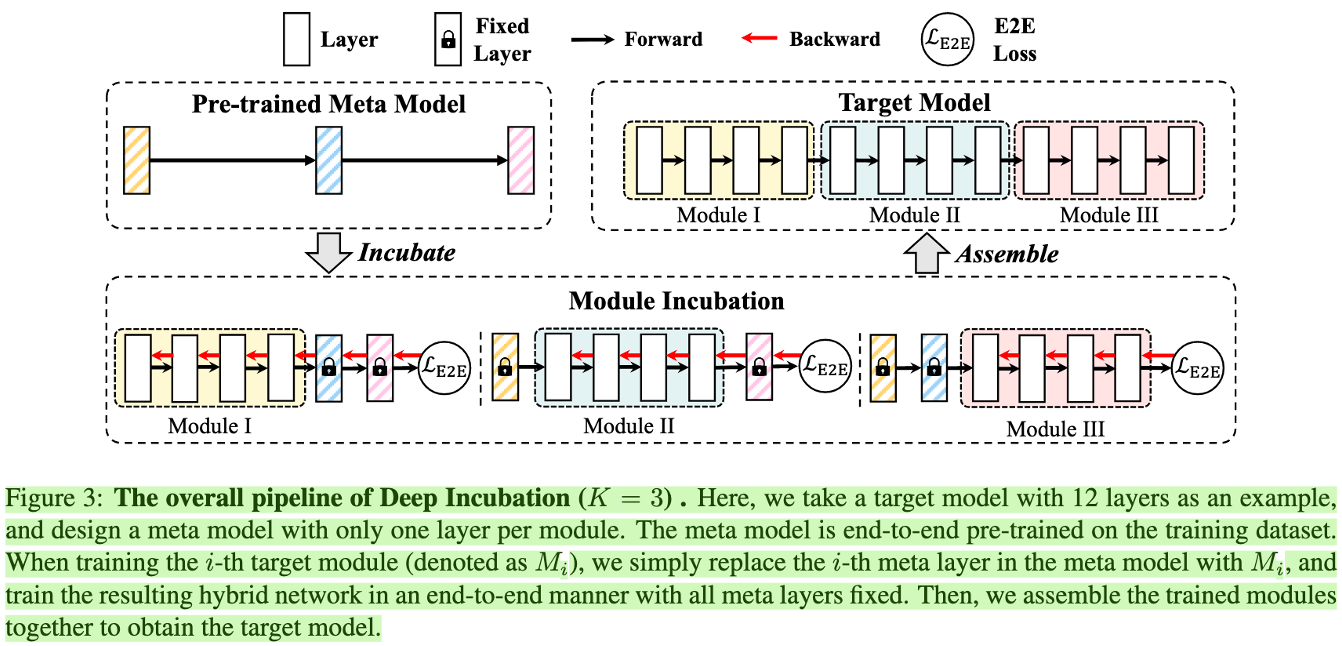
针对大模型训练 independency & compatibility 冲突的问题,设计了一种基于 Meta Model 的训练框架。且这种训练方式要比 E2E 效率 & 效果更优。
先训练一个 Meta Model 来 link 所有的 sub-module
再单独训练 sub-module,然后 replace Meta Model 中对应的部分

SpotTune
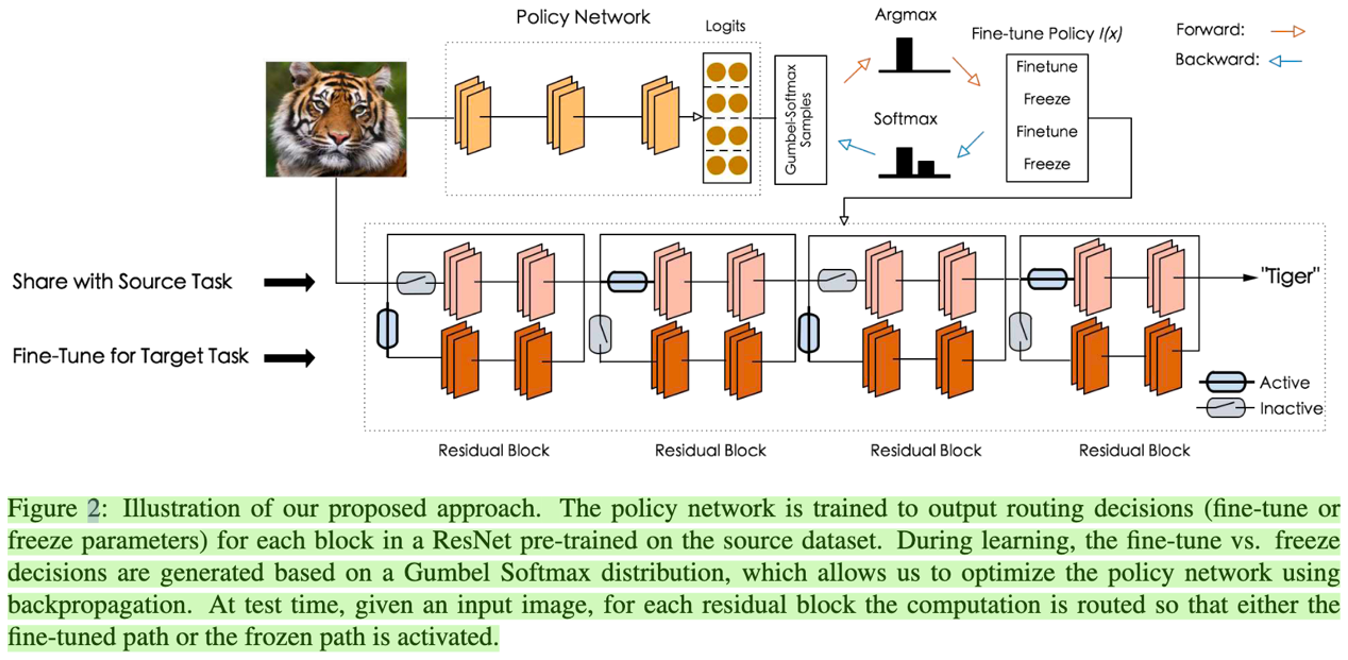
在最常见的 SFT 训练方式中,「freeze shared layer、fine-tune task layer」以及「full fine-tuning」是最常见的做法。但是前者在 target task 上的效果往往不如后者,而后者又容易产生 catastrophic forgetting 问题,且在 target dataset 不足的时候会存在严重的过拟合现象。针对这个问题,作者采用了一个 policy network 来在 instance-level 判断 input image 应该传到 fine-tuned layers 还是 pre-trained layers。在实践中,以一个 residual/transformer block 为单位,policy network 判断该 block 是否该被 freeze or fine-tune。大致思路如下:
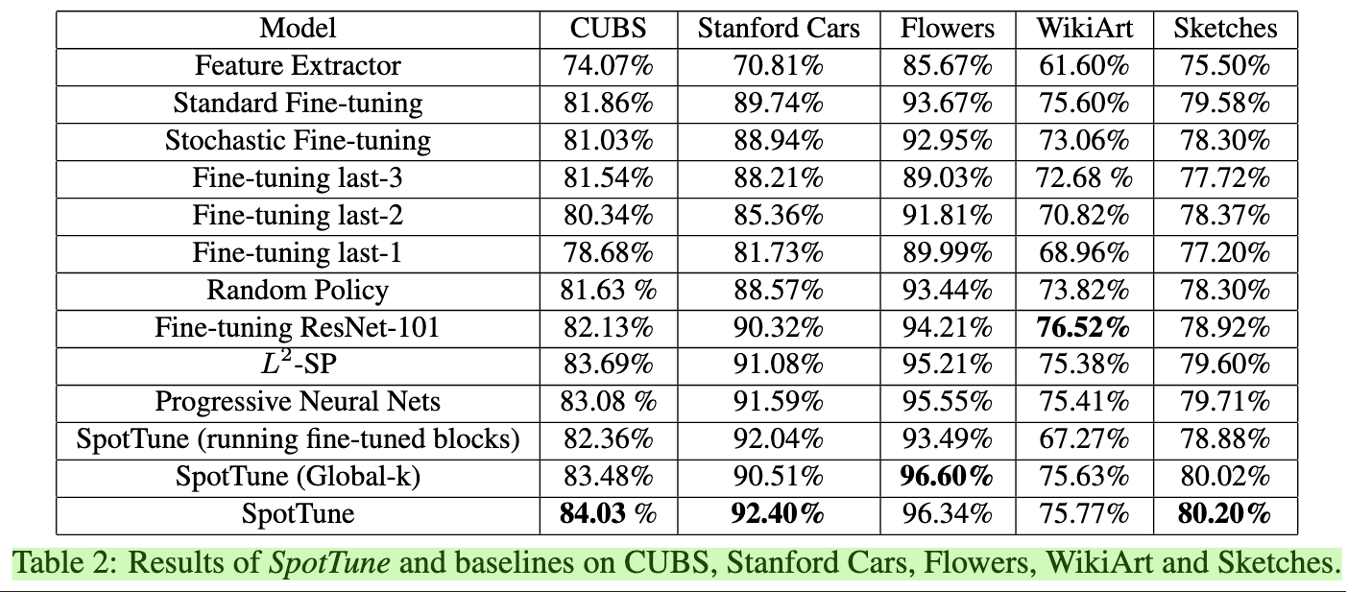
值得一提的是,SpotTune 不仅效率高,而且在下游的许多任务上,效果甚至超过了 full fine-tuning:
PEFT
PEFT (Parameter Efficient Fine-tuning) freeze 大部分参数,只更新少量参数。
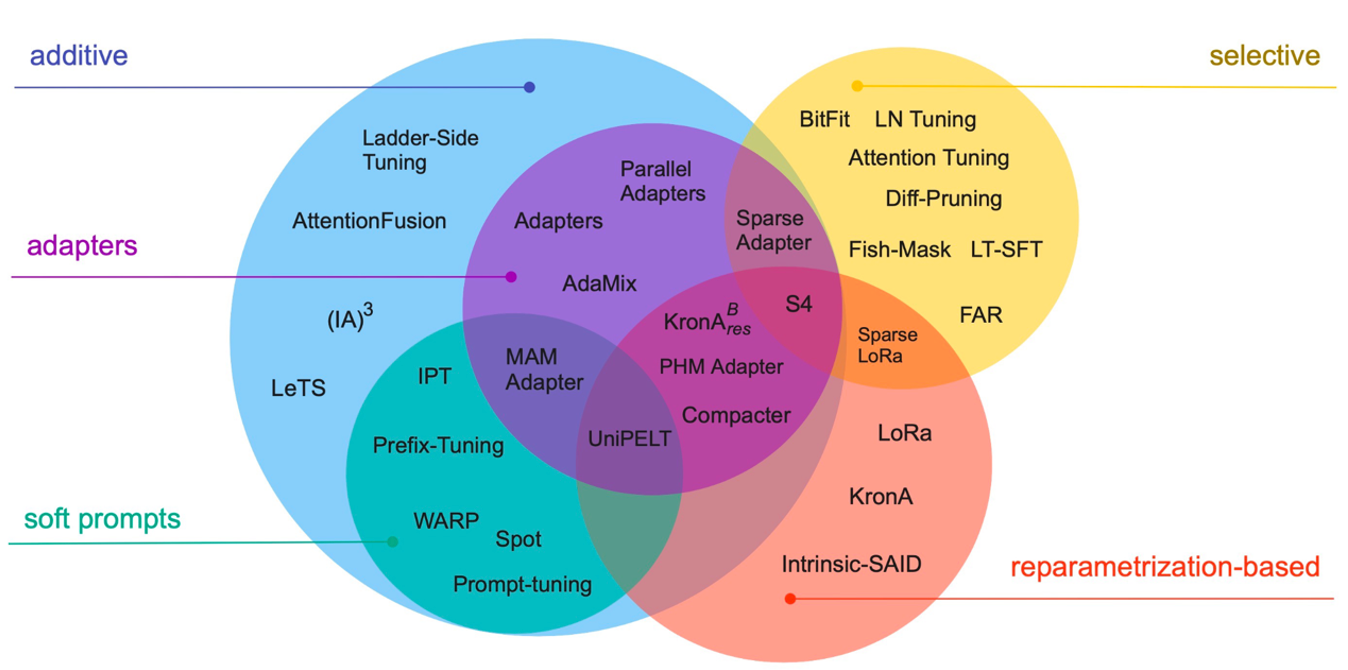
Infused Fine-tuning
Adapter-based
- P-tuning:仅针对 LLM embedding 加入新的参数
- P-tuning V2:将 LLM 的 embedding 和每一层前都加上新的参数
Sparse Fine-tuning
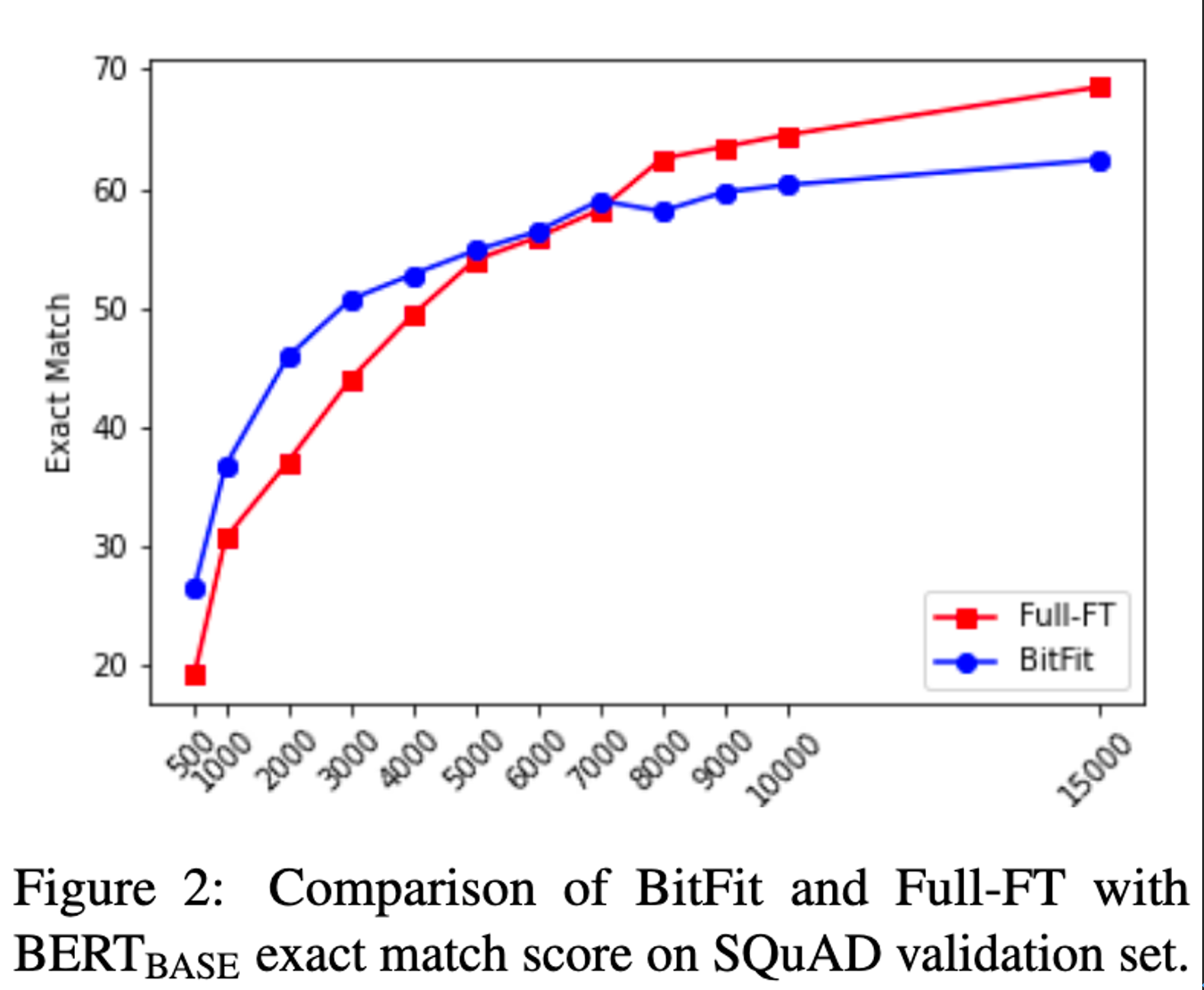
BitFit
仅仅 fine-tune bias 参数,weight 参数保持不变。居然能够和 fine-tune 所有参数达到相近的 performance。这也引出了大模型的另一个话题:finetuning is mainly about exposing knowledge induced by language-modeling training, rather than learning new task-specific linguistic knowledge.
LoRA
Soft Prompt
【附录】Hard Prompt:因为大模型具备较强的 zero-shot/few-shot 能力,所以 Hard Prompt 主要用 prompt 来提升 LLM 的效果。
因为 prompt text 属于 discrete input,当 training examples 很多的时候,优化起来比较困难。所以就有了 soft prompt,soft prompt 指的是在 input embedding 层面添加一层 trainable layer,使其能够参与 BP 更新网络参数,伪代码实现如下:
1 | def soft_prompted_model(input_ids): |
Hybrid
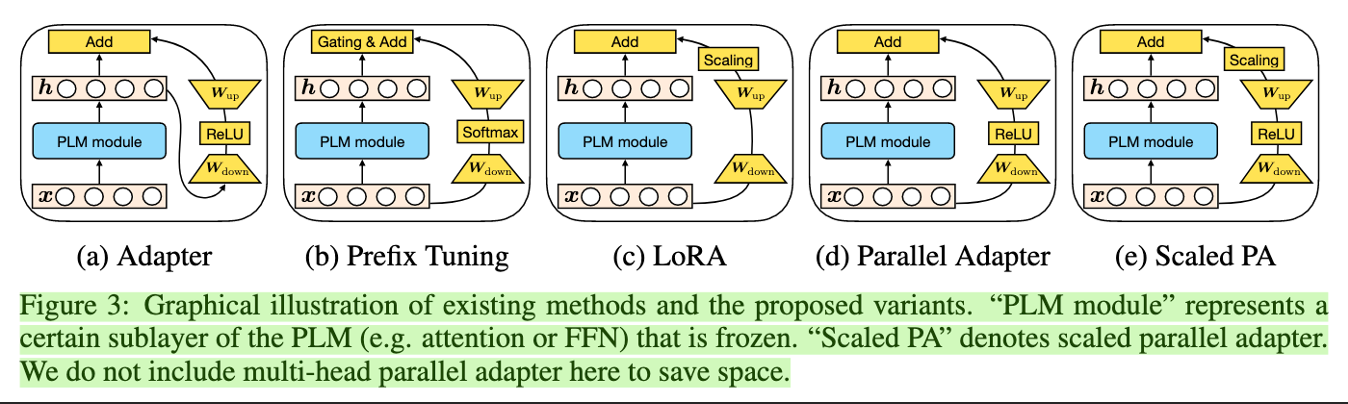
鉴于 LoRA、prompt-tuning、adapter 的有效性,scaled PA 提出了一种 unified framework 来同时融合这几种 fine-tune 方案。
Reference
- Parameter Efficient Fine-tuning
- Dong G, Yuan H, Lu K, et al. How Abilities in Large Language Models are Affected by Supervised Fine-tuning Data Composition[J]. arXiv preprint arXiv:2310.05492, 2023.
- Liu X, Zheng Y, Du Z, et al. GPT understands, too[J]. AI Open, 2023.
- Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//International Conference on Machine Learning. PMLR, 2019: 2790-2799.
- Zaken E B, Ravfogel S, Goldberg Y. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models[J]. arXiv preprint arXiv:2106.10199, 2021.
- He J, Zhou C, Ma X, et al. Towards a unified view of parameter-efficient transfer learning[J]. arXiv preprint arXiv:2110.04366, 2021.
- Ding N, Qin Y, Yang G, et al. Parameter-efficient fine-tuning of large-scale pre-trained language models[J]. Nature Machine Intelligence, 2023, 5(3): 220-235.
- Lialin V, Deshpande V, Rumshisky A. Scaling down to scale up: A guide to parameter-efficient fine-tuning[J]. arXiv preprint arXiv:2303.15647, 2023.
- Ni Z, Wang Y, Yu J, et al. Deep incubation: Training large models by divide-and-conquering[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023: 17335-17345.
- Guo Y, Shi H, Kumar A, et al. Spottune: transfer learning through adaptive fine-tuning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2019: 4805-4814.