
Introduction
随着抖音、快手等短视频平台的火热,视频分析也成了计算机视觉领域的研究热点。视频分类是视频内容分析的基础,以抖音为例,算法后台需要对用户实时拍摄上传的视频进行分类打上tag,然后再借助推荐算法分发到用户端。本文旨在记录一下video classification领域一些具有代表性的paper。
Deep CNN for Video Classification
Paper: Large-scale video classification with convolutional neural networks
这一篇差不多是第一个将DCNN应用到large scale video classification任务的,整体idea也比较简单。为了缓解DCNN参数过多导致的计算复杂度太高的问题,作者设计了一种two-stream的结构:一个context stream用来在low-resolution上进行学习,另一个fovea stream用来在high-resolution上进行学习。
Models
和image classification任务不同(在image classification任务中,我们会将size不同的image进行crop/resize到相同的size来作为CNN的输入),视频的长度、分辨率都可能不一样,这样就给分析带来了更大的挑战。在这篇文章中,作者将每一段视频看作是a bag of short, fixed-sized clips。因为每段clip包含一些连续的frame,我们就可以在时间维度上对网络的connectivity进行扩展,从而让模型学习到spatio-temporal features。作者在本文采用了3种处理方式(Early Fusion, Late Fusion, Slow Fusion)。
Time Information Fusion in CNNs
下面我们就来讨论一下跨temporal domain的信息融合方法:
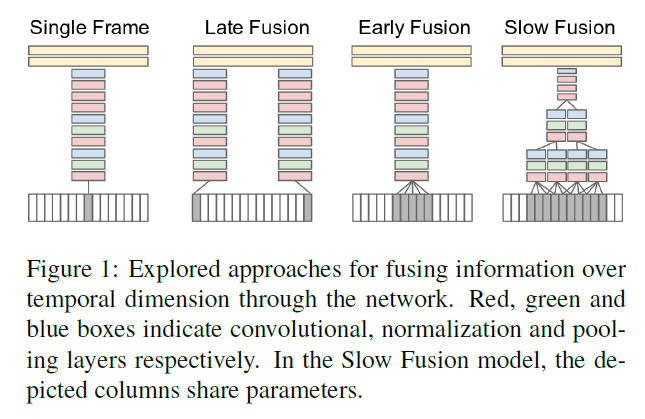
- Single-frame: 即不采用任何temporal-information fusion的方法,仅仅作为一种baseline。
- Early Fusion: 即在pixel-level直接连接整个time window的信息。代码实现层面是这样的:将singe-frame model的第一个conv layer改变为$11\times 11\times 3\times T$,其中$T$代表temporal extent。这种early and direct connectivity to pixel data的性质允许网络准确检测local motion direction and speed。
- Late Fusion: 即以15帧为距离,用两个共享参数的separate single-frame networks进行学习,然后在第一个全连接层对信息进行merge。这样一来,任何一个single-frame network都不能检测出任何motion,但是第一个全连接层可以通过比对两个networks的输出来计算global motion。
- Slow Fusion: 这种方式的高层可以在spatial和temporal维度获取更多的global information。代码实现层面是这样的:
This is implemented by extending the connectivity of all convolutional layers in time and carrying out temporal convolutions in addition to spatial convolutions to compute activations, as seen in [1, 10]. In the model we use, the first convolutional layer is extended to apply every filter of temporal extent $T = 4$ on an input clip of 10 frames through valid convolution with stride 2 and produces 4 responses in time. The second and third layers above iterate this process with filters of temporal extent $T = 2$ and stride 2. Thus, the third convolutional layer has access to information across all 10 input frames.
Network Architecture
本文用到的two-stream网络结构是这样的:一个stream用来接收对原视频帧下采样后的作为输入;另一个stream接收原视频帧center crop的作为输入。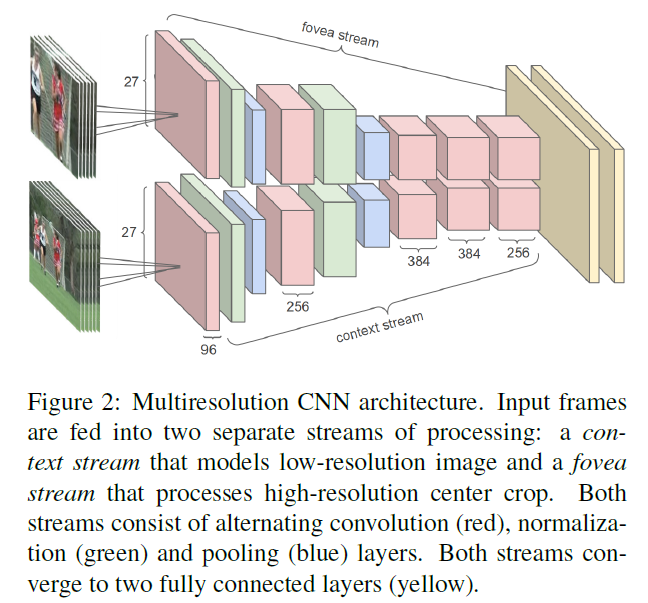
另外,在实验中,作者发现:
- context-stream学习到了更多的color feature。
- high-resolution fovea-stream学习到了high frequency的grayscale filter信息。
Reference
- Karpathy, Andrej, et al. “Large-scale video classification with convolutional neural networks.” Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014.